
Redis进阶理论
一、缓存问题
1. 缓存穿透
1.1 什么是缓存穿透
缓存穿透是指,当查询数据时,如果数据库中不存在数据,那么也就不会把数据写入缓存中,那么这个数据也就会一直不纯在,所以每次访问这个数据的时候,都永远会直接访问数据库。当大量查询不纯在的数据时,就会直接访问数据库,请求量大的时候数据库可能就会宕机。

1.2 如何解决缓存穿透
在数据库中查询到不存在的数据时,把这个不存在的数据写入缓存(key:xx value:null)
优点:方便快捷,实现简单
缺点:消耗内存,可能会发送数据不一致问题:把空数据写入缓存后,如果后面数据库中的数据不为空了,那么缓存中的数据还未更新,那么读取到的数据仍然为空

在接口层增加校验,如对id做校验,id<0的直接拦截
使用布隆过滤器实现(重点介绍)
优点:占用内存少,不存在多余的key
缺点:
实现复杂
存在误判的可能

1.3 布隆过滤器
用于快速查询一个元素是否存在
1.3.1 原理
开始的时候,先初始一个比较大的数组,里面就用于存放二进制0和1。当一个key来到的时候,就会对这个key进行3次hash计算,取模于数组的长度,最后会得到3个值,然后就会把这3个值对应的数组下标里存放的元素从0改成1,这样3个数组元素就能确定一个key是否存在了。

当然,这种方法也有缺点,就是可能会发生hash冲突,从而导致一定概率的误判。解决方法就是把初始数组的时候,把这个数字开的尽可能的大一些,这样就可以尽可能的避免冲突。但是开的太大又会消耗过多的内存。所以一般情况下我们都会运行5%的误差。
1.3.2 实现
基于redission实现布隆过滤器(待做)
2. 缓存击穿
2.1 什么是缓存击穿
当缓存中有某个数据被高并发访问时,此时该缓存突然就不存在了(缓存过期,又或者缓存更新时消耗时间过长导致缓存短暂的不存在),那么此时就会有大量的请求直接访问到数据库上,导致数据库宕机。缓存击穿尝尝发送在热点数据中
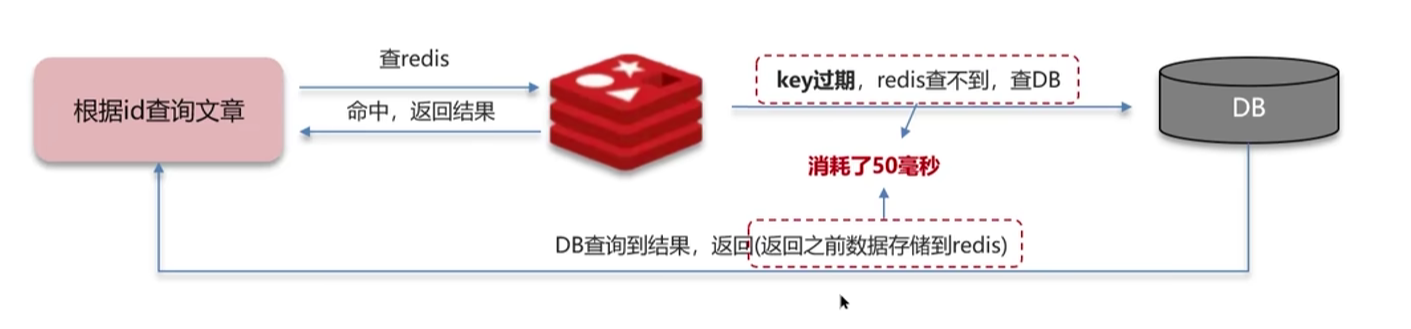
2.2 如何解决缓存击穿
2.2.1 互斥锁/分布式锁
当一个线程查询缓存未命中后,就会获取一个互斥锁,该互斥锁只能同时有一个线程拥有
如果有其他线程这时候查询缓存也未命中,也想获取锁,那么就会一直失败重试
第一个获取互斥锁的线程来负责查询数据重构缓存,写入缓存后就释放锁
释放锁后,其他线程就可以读取到数据了

优点:能够保证数据的强一致性,实现简单
缺点:性能比较差。多个线程会等待一个线程
2.2.2 逻辑过期
逻辑过期就是在写入缓存的时候不设置缓存过期时间,但是多写一个逻辑的缓存有效时间字段。当某一个线程线程在查询缓存命中后,就会对那个字段进行判断,如果逻辑过期了,该线程就会获取一个互斥锁,同时新开一个线程来查询数据库中的最新数据并更新缓存,更新完数据后那个新的线程就会释放锁。但是注意,原来的那个线程在开新线程来更新数据后,并不会等待新线程更新缓存完毕后,才执行查询缓存操作。而是在开新线程后,自己又执行查询缓存操作 并返回,只不过这时候查询到是旧的数据而已。

优点:线程无须等待,性能好
缺点:不保证一致性,有额外内存消耗,实现复杂
3.缓存雪崩
3.1 什么是缓存雪崩
缓存雪崩是指,当缓存中有大量的key同时失效或者Redis服务器宕机,就会导致有大量的请求发送到数据库上,导致数据压力过大甚至宕机。

3.2解决方案
给不同的Key的有效时间添加随机值,这样就可以避免大量的Key同时失效了
使用Redis集群,提供服务的可用性,一个redis服务宕机了,还可以使用其他的redis服务
比如:哨兵模式、集群模式
在缓存业务上添加降级限流策略
比如:nginx或者spring cloud gateway
给业务添加多级缓存
比如:使用Guava或Caffeine作一级缓存,使用redis做二级缓存
4.双写一致
修改了数据库的数据,缓存中的数据也要保持同步修改,让缓存中的数据和数据库中的数据保持一致。
4.1 问题
一般情况下:会出脏读
先删缓存,在更新数据库,最后更新缓存
出现的问题:
线程1要更新数据,先删除缓存
线程2要读数据,先读缓存,读不到,然后直接读数据库,读出X,最后线程2把X写入了缓存,此时缓存中又是X
线程1更新数据库,把数据库更新为Y
最终的结果是,数据库中存的是Y,但是缓存中存的是X

先更新数据库,再删缓存,然后更新缓存
出现的问题
假设初始时,数据库有值X,缓存中的X已过期
线程1 查找数据,缓存中没有,读出数据库中的X
线程2 更新数据,先更新数据库, X更新成Y
线程2 更新缓存,把空缓存更新成Y
线程1 更新缓存,把Y更新成X
最终 缓存X 数据库Y
数据不一致

4.2 解决方案
从上面的分析我们可以发现,出现脏读的结果时,都是因为缓存的数据和数据库中的数据不一致,缓存中保留了旧的数据,所以我们只要再最后在删除一次缓存就可以解决这个问题
4.2.1延时双删
删缓存——>更新数据库——>延时一会再删缓存
我们最后一次删除缓存要延时一会呢? 因为在开发中,我们使用的是主从数据库的开发模式,即有两个一模一样的数据库,用来开发,一个用来读,一个用来写,这两个数据库上面的数据变更都会相互同步给对方,而同步是需要时间的,所以我们在更新数据库后,在延时一会在删除缓存。
但这样也有一个问题,就是这个延时的时间长度不是固定的,我们不能确定,所以延时双删的策略也有一定的缺点

4.2.2 使用互斥锁解决
方案一:
在一个线程读/写数据时上锁,不运行其他数据读、写数据。这样就保证了数据的强一致性。但是效率比较低,适用于严格要求数据一致性的场景

方案二:
在一个线程执行读操作的时候,就获取共享锁,共享锁只运行其他线程进行读操作。
在一个线程执行写操作的事,就获取排他锁,排它锁在没有开锁之前,不允许其他线程进行读写操作。
一般来说放在缓存中的数据都是读多写少的,所以这种方案十分合理,也常用。

具体实习技术请参考:这篇文章(待做)
5.Redis是如何做数据持久化的?
5.1 RDB
RDB(Redis Database Backup file): Redis数据库恢复文件,也叫做Redis数据快照。简单来说,就把内存中的数据文件拷贝到磁盘中,需要恢复的时候就直接从磁盘中读取恢复
如何开启RDB机制
redis是默认开启RDB机制的,并且有默认的触发时机,如果要更改触发时机可以在
redis.conf文件中修改
原理:
由于Linux和Windows系统中的进程,不能直接操作物理内存的,只能操作虚拟内存
所以Redis的主进程中会存有一张页表,这张页表记录着虚拟内存和操作系统物理量内存的映射关系,通过页表Redis就能对物理内存进行间接的读写操作了
当执行Redis数据快照机制时,Redis主进程就会被fork出一个子进程(理解为拷贝出一个子进程),这个子进程里面的内容数据跟主进程一样,包含了页表,这样就和主进程实现了物理内存共享,子进程就可以直接读取到内存中的缓存数据,然后把内存中的数据写入系统磁盘中,形成RDB二进制文件。当Redis服务宕机重启时,就会从磁盘中读取RDB文件进行数据恢复。
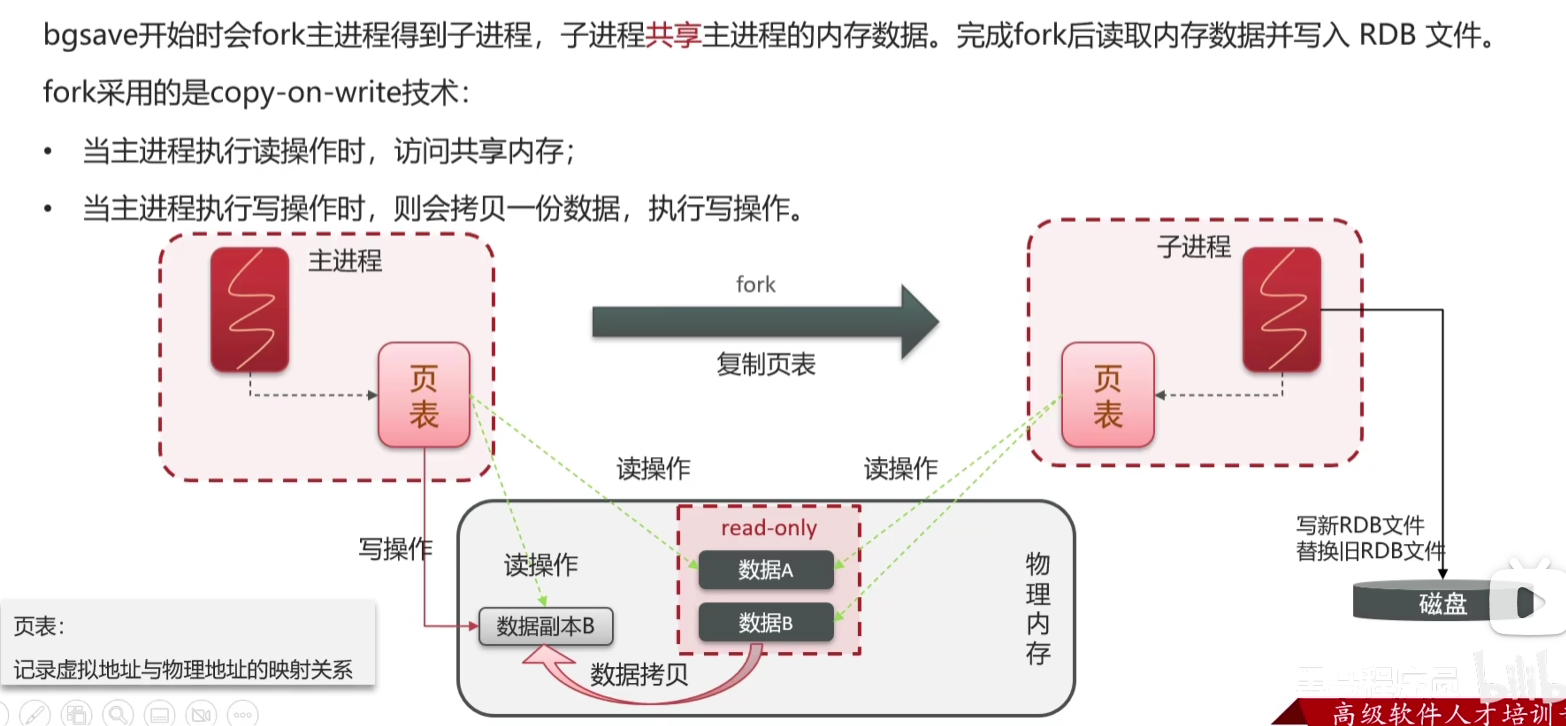
既然子进程和主进程实现了共享,那么子进程在拷贝内存中的数据的时候,如果主进程对内存进行写操作,这不就会出现脏读了吗?
实际上Redis才用的是Copy-On-Write的技术(写时复制),子进程在复制内存数据到磁盘上时,内存中的那份数据已经变限制为read-only只读的了,而主线程要写数据时,就要先拷贝一份原数据出来,在拷贝的数据上进行写操作,然后最最后更新自己的页表,以后主进程读数据也是在拷贝出来的数据上进行读取了。
5.2 AOF
AOF(Append Only File) 追加文件 持久化方式。
原理:
AOF会记录Redis中所有的命令执行记录形成一个AOF文本文件,当Redis重启时,就会读取这个文件,执行里面的记录命令来恢复数据


5.3 对比

6. 数据过期策略
先说结论:Redis使用的是惰性策略+定期删除策略 同时使用
6.1 惰性策略
平时不对key进行检测,只有要用到该key(查询,修改)的时候,才去检查改key是否过期,如果过期了就删除
优点:对CPU友好,只有在用到key的时候,才会检查该key是否过期
缺点:对内存不友好,会有很多过期的key留在内存中占用
6.2 定期删除
slow模式
定时任务。执行默认频率为10Hz,每次不超过25ms。(为了尽可能的减少Redis的读写操作的影响)
可以在redis.conf配置文件中来调整这两个参数
fast模式
执行频率不固定,但每两次之间的间隔不少于2ms,每次耗时不超过1ms
优点:内存友好,会定期清理过期的key。CPU友好,可以通过修改执行的频率和时间,来减少对CPU的消耗
缺点:不好控制执行的频率和时间
7.数据淘汰策略
当内存爆满时,redis才会触发数据淘汰策略。一共8总
7.1 8种策略
noeviction:不淘汰任何Key,内存满时不允许写入数据。这是默认策略
volatile-ttl:对所有设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
allkeys-random:对全体key,随机进行淘汰。
volatile-random:对设置了TTL的key,随机进行淘汰。
allkeys-lru:对全体key,基于LRU算法进行淘汰
volatile-lru:对设置了TTL的key,基于LRU算法进行淘汰
allkeys-lfu:对全体key,基于LFU算法进行淘汰
volatile-lfu:对设置了TTL的key,基于LFU算法进行淘汰
知识:
LRU(Least Recently Used)最近最少使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU(Least Frequently Used)最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
7.2 使用建议
如果业务中,有明显的数据冷热区分时
使用allkeys-lru策略,对最近使用最少的数据进行淘汰,保留最近最尝使用的数据
没有明显的数据冷热区分时
使用allkeys-random策略,对全体key进行随机淘汰
如果业务有置顶的需求
对置顶数据 不设置过期时间,并使用volatile-lru策略,对设置了TTL的key进行LRU算法淘汰,淘汰掉最近使用最少的且设计了过期时间的数据
如果有 短时间内高频访问 的数据
使用,volatile-lfu 或者 allkeys-lfu 策略

二、分布式锁
满足在分布式或者集群环境下,多线程可见并且互斥的锁
1. 什么情况下需要用到分布式锁
集群环境下的 抢单,优惠券,定时任务,幂等性 等场景
比如:
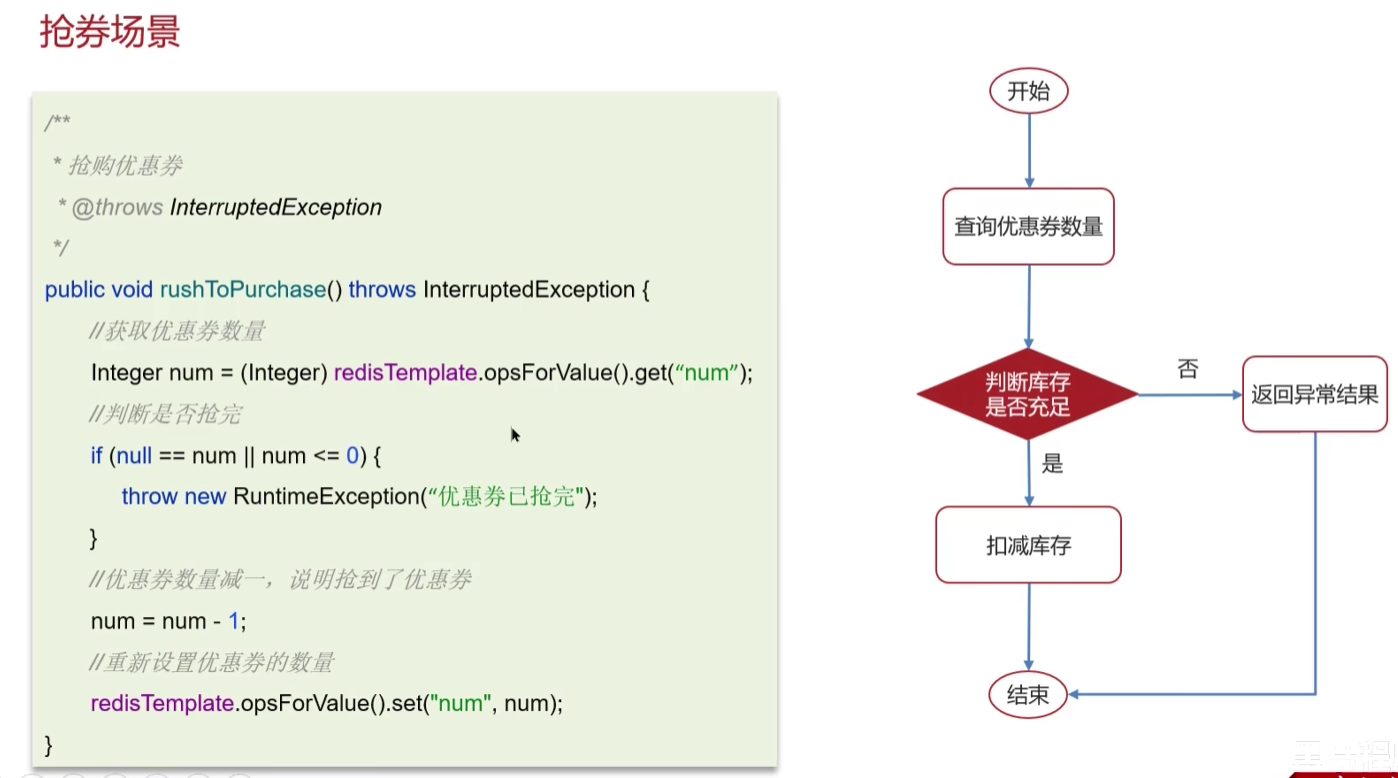
在抢购优惠券的时候,先获取优惠券的数量,然后对优惠券的数量进行判断,如果大于0了,就对优惠券的数量进行减1操作。
这种情况下,如果是多线程高并发的场景下,就会出现这样的情况:
优惠券还剩1张
线程1:查询优惠卷数量为1
线程1:对优惠卷数量进行判断
线程2:查询优惠卷数量为1
线程1:数量充足,进行减1
线程2: 对优惠卷数量进行判断,
线程2:因为线程2前面查询到的数量为1,所以判断优惠卷数量充足,又会进行减1的操作
这就是超卖了

2. 解决方案
2.1 本地锁synchronized
这种锁仅适用于单体架构,且只启动了一台服务器的情况下使用。因为synchronized是java的内置锁,只能控制自己服务器的进程,不能控制其他服务器
在一个线程要调用购买优惠卷的逻辑时,就先获取一把synchronized锁,synchronized锁在同一个服务业务上只能有一个线程拥有,当调用玩购买优惠卷的逻辑后,在释放锁,让其他线程获取。
