
基于Redis的Sorted Set数据结构,实现关注消息推送(Feed 流)
一、需求
作者发布文章(动态、帖子、博客等)的同时,推送到粉丝的收件箱
收件箱满足根据时间戳排序
查询收件箱时,可以实现分页查询
二、思路分析
传统分页
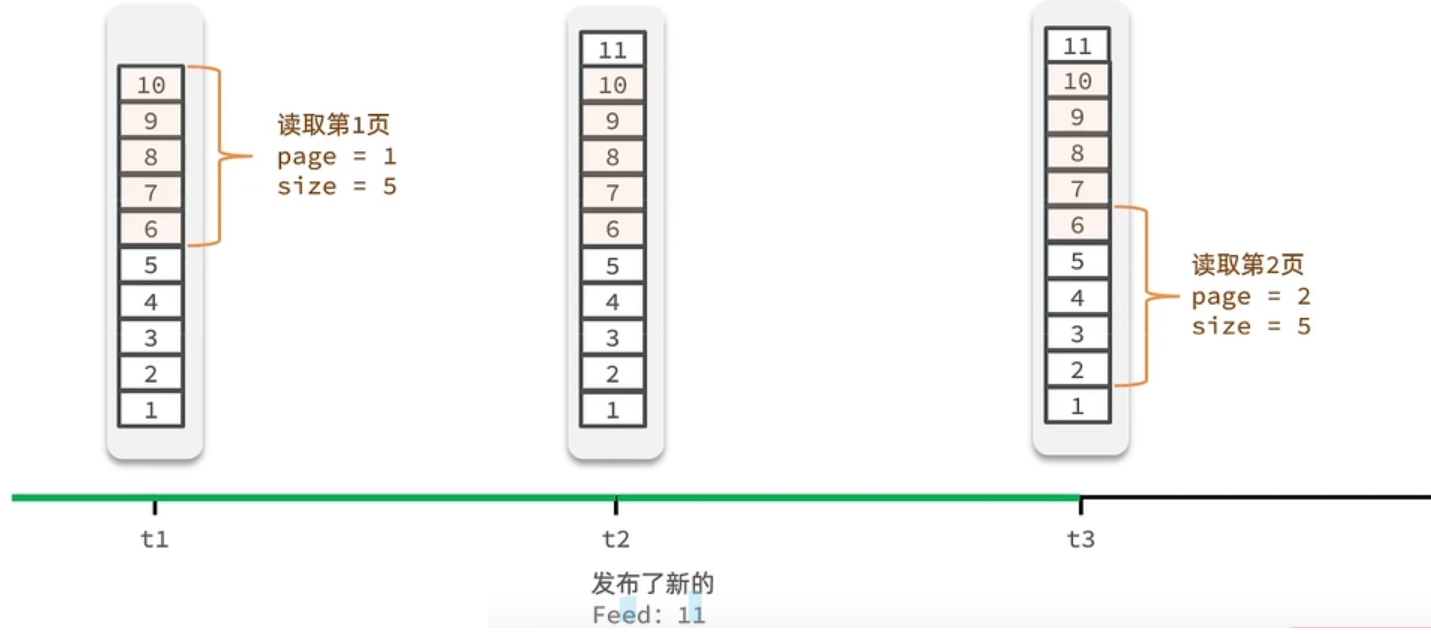
Feed流中的数据会不断更新,所以数据的角标也在变化,因此不能采用传统的分页模式。
传统了分页在feed流是不适用的,因为我们的数据会随时发生变化
假设在t1 时刻,我们去读取第一页,此时page = 1 ,size = 5 ,那么我们拿到的就是10~6 这几条记录,假设现在t2时候又发布了一条记录,此时t3 时刻,我们来读取第二页,读取第二页传入的参数是page=2 ,size=5 ,那么此时读取到的第二页实际上是从6 开始,然后是6~2 ,那么我们就读取到了重复的数据,所以feed流的分页,不能采用原始方案来做。
Feed流的滚动分页
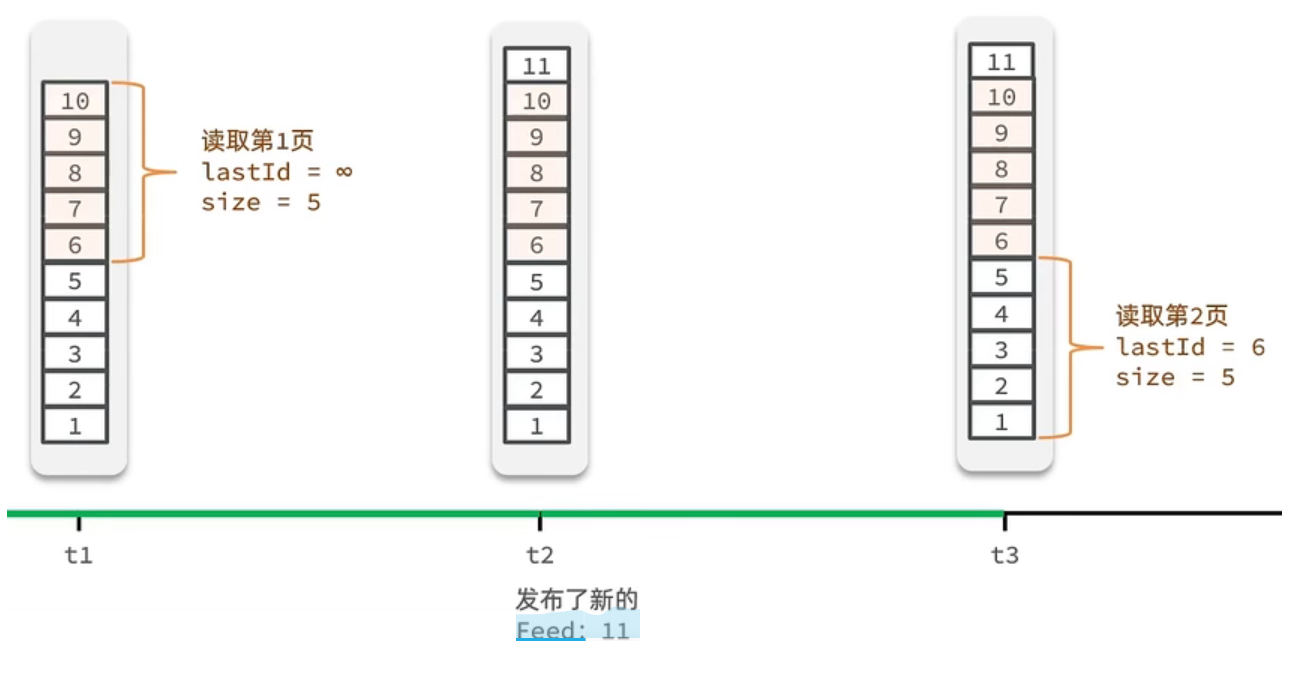
我们需要记录每次操作的最后一条,然后从这个位置开始去读取数据
举个例子:我们从t1时刻开始,拿第一页数据,拿到了10~6,然后记录下当前最后一次拿取的记录,就是6,t2时刻发布了新的记录,此时这个11放到最顶上,但是不会影响我们之前记录的6,此时t3时刻来拿第二页,第二页这个时候拿数据,还是从6后一点的5去拿,就拿到了5-1的记录。我们这个地方可以采用sortedSet来做,可以进行范围查询,并且还可以记录当前获取数据时间戳最小值,就可以实现滚动分页了
三、具体实现
作者发布文章的同时,把文章推送到粉丝的邮箱
@Override
public Result saveBlog(Blog blog) {
// 1.获取登录用户,省略
// 2.保存探店笔记,省略
// 3.查询笔记作者的所有粉丝 select * from tb_follow where follow_user_id = ?
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
// 4.推送笔记id给所有粉丝,业务名+用户id作为key,博客id作为value。这就是用户的收件箱
for (Follow follow : follows) {
// 4.1.获取粉丝id
Long userId = follow.getUserId();
// 4.2.推送
String key = FEED_KEY + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 5.返回id
return Result.ok(blog.getId());
}粉丝查看自己的邮箱
1、每次查询完成后,我们要分析出查询出数据的最小时间戳,这个值会作为下一次查询的条件
2、我们需要找到与上一次查询相同的查询个数作为偏移量,下次查询时,跳过这些查询过的数据,拿到我们需要的数据
综上:我们的请求参数中就需要携带 lastId:上一次查询的最小时间戳 和偏移量这两个参数。
一、定义出来具体的返回值实体类
@Data
public class ScrollResult {
private List<?> list;
private Long minTime;
private Integer offset;
}BlogController
注意:RequestParam 表示接受url地址栏传参的注解,当方法上参数的名称和url地址栏不相同时,可以通过RequestParam 来进行指定
@GetMapping("/of/follow")
public Result queryBlogOfFollow(
@RequestParam("lastId") Long max, @RequestParam(value = "offset", defaultValue = "0") Integer offset){
return blogService.queryBlogOfFollow(max, offset);
}BlogServiceImpl
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
// 1.获取当前用户
Long userId = UserHolder.getUser().getId();
// 2.查询收件箱 ZREVRANGEBYSCORE key Max Min LIMIT offset count
String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
// 3.非空判断
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
// 4.解析数据:blogId、minTime(时间戳)、offset
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0; / / 2
int os = 1; // 2
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) { // 5 4 4 2 2
// 4.1.获取id
ids.add(Long.valueOf(tuple.getValue()));
// 4.2.获取分数(时间戳)
long time = tuple.getScore().longValue();
if(time == minTime){
os++;
}else{
minTime = time;
os = 1;
}
}
// 5.根据id查询blog
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
for (Blog blog : blogs) {
// 5.1.查询blog有关的用户
queryBlogUser(blog);
// 5.2.查询blog是否被点赞
isBlogLiked(blog);
}
// 6.封装并返回
ScrollResult r = new ScrollResult();
r.setList(blogs);
r.setOffset(os);
r.setMinTime(minTime);
return Result.ok(r);
}